
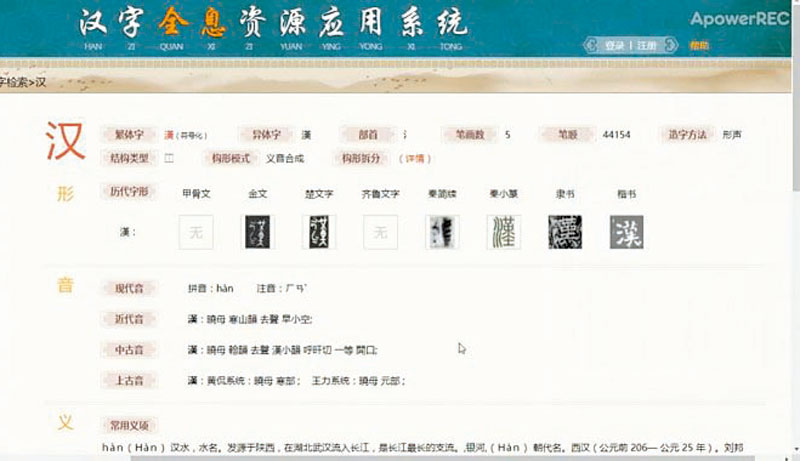
大陸的「漢字全息資源應用系統」正式啟動上線。以後準確查找一個難檢字的相關資訊再也不用跑遍古籍閱覽室,只需輕點滑鼠,登錄這個系統,點擊現代通用字集,搜索要查找的字,不僅能夠顯示其現代字形、字音、字義資訊,還可以查到該字從甲骨文、金文到篆書、楷書的歷史字形演變過程,一指就搞定。
屬於大陸國家語委重大基礎資源建設專案的「通用漢字全息資料庫建設」標誌性成果的漢字全息資源應用系統,日前正式啟動上線。目的在運用現代中文資訊處理技術,構建一個具有多維關聯關係、科學系統、高效實用的漢字全息資料庫。

涵蓋五大方面資訊
本期上線的系統涵蓋字元集4種,其中常用字集3500字,通用規範字8105字,古籍印刷字16490字,全字元集81722字;還有辭書20種,古籍文獻60種,歷代字形圖415675個。其中包括大量的圖形資訊資源和文本資訊資源,分別來自古文字拓片、文字編、規範字表、編碼字元集、歷代辭書、經典文獻、中小學語文教材等,涵蓋了古今各個時期文字的形、音、義、用、碼五大方面的重要資訊。
「如果說建立資料庫是給漢字家族繪製一張家譜,那麼建立關聯則是搞清譜系、輩分等關係。首先是漢字屬性的分解,構建一個具有多角度關係的漢字實用資料庫,必須以漢字的屬性作為基本的依託。」北京師範大學教授王甯指出,團隊從20世紀90年代開始總結漢字的屬性,除形、音、義之外,還增加碼、用兩個部分。碼是漢字在電腦中的編碼,用是漢字的使用,而且做了大量的屬性細化研究,這樣就將籠統的漢字個體的資源庫,改造為漢字的屬性庫,解決關聯的多角度問題。
漢字殿堂有血有肉
系統包括常用字集、現代通用字集、古籍印刷通用字集、全字元集等。常用字集可以滿足中小學基礎教育領域的一般需要;現代通用字集可以滿足社會文化領域一般漢字使用者的需要;古籍印刷通用字集面向具備一定古漢語知識、閱讀一般古籍文獻的用戶;全字元集則可以滿足漢字研究的專業人士需求,為專業研究提供支援。
在這項系統中,漢字分為常用-通用-適用-罕用-無用5個層。第一、二層次涵蓋36000字,以外的字只存記憶,不做深度開發,這樣一方面可以在應用中擴大有用資訊的使用度,另一方面將垃圾資訊、無用資訊退出關聯,不干擾有效資訊的集合和調用。北京師範大學教授王立軍就表示,無論是初學漢字的小學生,或研究漢字的學者,系統都可以提供相應的幫助。
在全球,無論是簡體或繁體,漢字不是一個個「孤零零」的符號,漢語文獻正像軀體的血肉,豐富著漢字殿堂的內容,並發揚光大。(記者/李鋅銅)